Alexandros Bampoulidis, RSA FG, WP5 – De-Anonymisation Task
Personal data is data that contains information about individuals and is commonly used in the industry and academia for research and innovation purposes. However, with sharing these kind of data comes the danger of a privacy breach, posing a threat to the privacy of the individuals whose information is contained in the dataset.
A common misconception is that removing all personally identifying information (PII), such as name, address, etc., makes the data anonymous. Extensive research in de-anonymisation – the process of identifying individuals in a dataset – has proven this belief wrong. In Simple Demographics Often Identify People Uniquely (2000), Sweeney showed that 87% of the U.S. population is uniquely identifiable by the combination of their gender, date of birth and ZIP code. Such attributes, whose combination can serve as a unique identifier, are called quasi-identifiers (QIs).
In Safe-DEED, we are investigating the de-anonymisation of datasets, in order to raise privacy red flags, and measures to reduce the risk of de-anonymisation. Specifically, we are conducting these investigations on the use case of Work Package 6, which consists of a customer relationship management (CRM) dataset provided by the Greek telecommunications provider Forthnet. To this purpose, we defined a procedure consisting of 3 steps: data landspace analysis, threat analysis, and anonymisation measures.
The purpose of data landscape analysis is to raise red flags through a simulation of de-anonymisation attacks performed on a dataset. It consists of gathering external information, mostly from social media, that could be matched to the information contained in the dataset, and processing the dataset and the information gathered. This step of the procedure reveals how and in which way individuals can be identified in a dataset, given the information that is currently available.
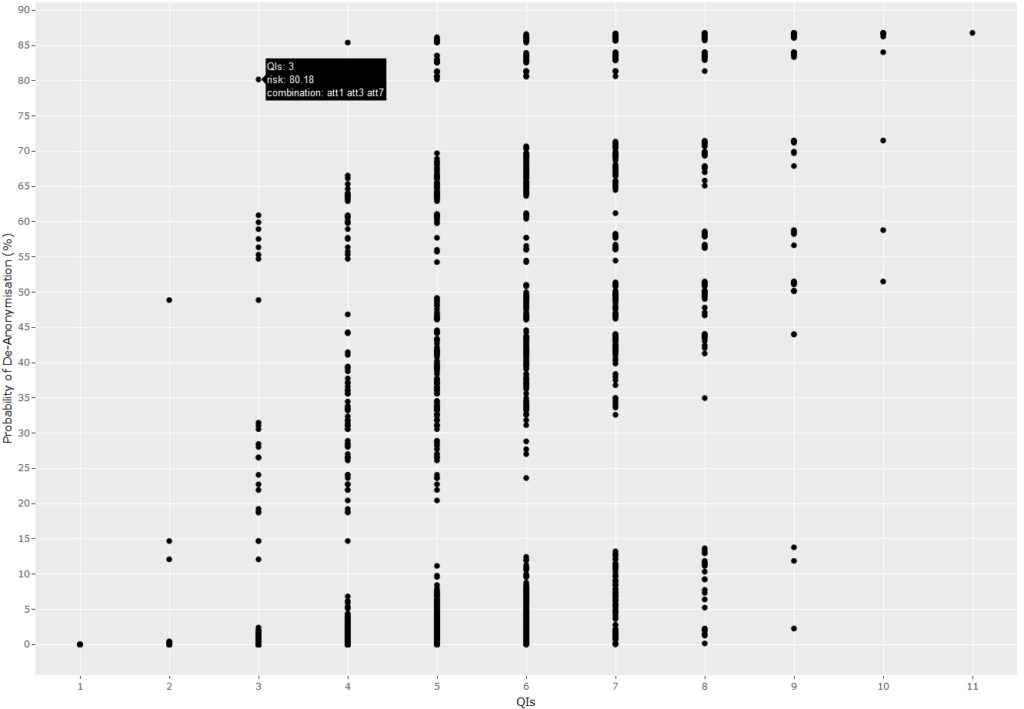
The purpose of threat analysis is to raise red flags through a de-anonymisability analysis of a dataset through which the QIs that are critical in the de-anonymisation of individuals may be identified and the extent to which a dataset is de-anonymisable is revealed. This step of the procedure is supported by tools and the figure below depicts an example output of such a tool applied on a dataset consisting of 11 QIs. Each point represents a unique combination of QIs – 2047 unique combinations for 11 QIs – and indicates the percentage of individuals that are uniquely identifiable by the respective combination of QIs. In this specific example, it can be seen that attributes 1, 3 and 7 are critical in de-anonymisation, since 80% of the individuals are uniquely identifiable by their combination, while the combination of all QIs uniquely identifies 86% of the individuals.
In order to mitigate the de-anonymisation risks, anonymisation measures, beyond removing PII, need to be taken. Such measures rely on distorting the original values of a dataset so as to protect the privacy of its individuals, but at the cost of its utility. A challenge in this procedure is to find the golden mean between privacy and utility – the point of having high privacy, while still having a valuable dataset.
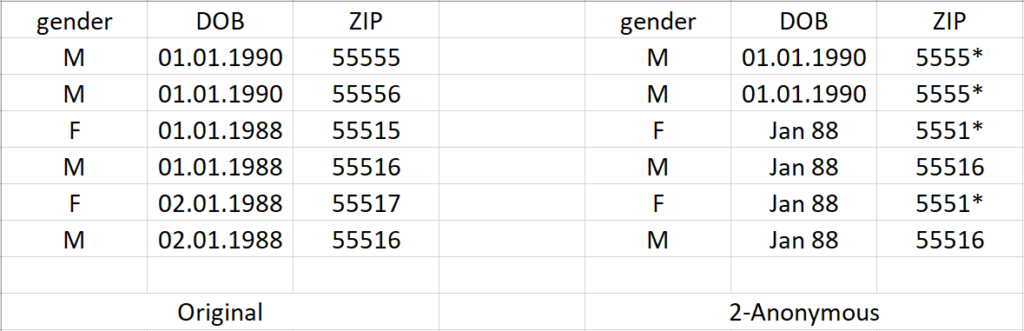
As an example, the most basic anonymity principle is called k-anonymity and states that every individual in a dataset cannot not be distinguished by at least k-1 other individuals, i.e. the maximum probability of identifying any individual is 1/k. This can be achieved by defining generalisation hierarchies that describe the abstract values that could replace the original values of a dataset. The figure below depicts a transformation of the original dataset conforming to 2-anonymity – every individual has at least 1 other individual with the same QIs’ values. In this example, some of the exact birth dates were generalised to month-year, while some of the ZIP codes were cut to 4 digits. The higher the k would have been, the more distorted the values would have been.